Explainable AI for text summarization of legal documents

Nina Hristozova, Data Scientist, and Milda Norkute, Senior Designer, Thomson Reuters, discuss explainable AI for text summarization of legal documents and tailoring how to explain your model based on the needs of your user.
Explainable AI
Explainable Artificial Intelligence (XAI) is an umbrella term for a range of techniques, algorithms, and methods, which accompany outputs from Artificial Intelligence (AI) systems with explanations. It addresses the often undesired black-box nature of many AI systems, and subsequently allows users to understand, trust, and make informed decisions when using AI solutions [1].
Background
The rapidly growing adoption of AI technologies using opaque deep neural networks has prompted both academic and public interest in explainability. This issue appears in popular press, industry practices, regulations, as well as many recent papers published in AI and related disciplines.
Figure 1 below shows the evolution of the number of total publications whose title, abstract or keywords refer to the field of XAI during the last years. Data was retrieved from Scopus in 2019. We can see that the need for interpretable AI models grew over time, yet it has not been until 2017 when the interest in techniques to explain AI models (in green) has permeated throughout the research community [1]. It is possible one of the reasons for this was the introduction of “GDPR”, also known as the “General Data Protection Regulation” introduced in 2016 in the European Union (EU), which includes a “right to explanation”.

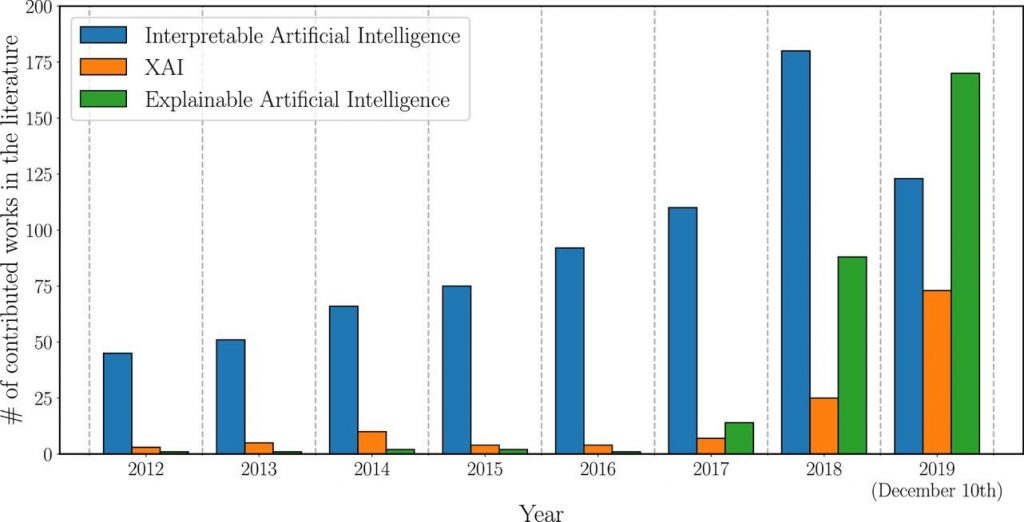
In Figure 1 we also see a gradually growing interest in interpretability. Explainability should not be confused with interpretability. The latter is about the extent to which one is able to predict what is going to happen, given a change in input or algorithmic parameters. It is about one’s ability to discern the mechanics without necessarily knowing why. Meanwhile, explainability is the extent to which the internal mechanics of a machine or deep learning system can be explained in human terms [2]. However, the difference is subtle. We will stay focused on explainability for the rest of this article, but to learn more about interpretability see this resource.
XAI for whom?
The purpose of explainability in AI models can vary greatly based on the audience. Generally, five main audience types can be identified: domain experts and users of the model, interacting with its outputs directly, users affected by model’s decisions, regulatory entities, creators of the model – data scientists, product owners and others, managers and executive board members [1]. See Figure 2 below to learn more about the different explainability needs of some of these audiences.

For example, the purpose of having explainability for the users of the model is to trust the model, while users affected by model decisions could benefit from explainability by understanding their situation better, verify whether the decisions were fair. Since these audiences have different goals, this means that an explanation that may be considered as good by one type of audience may not be sufficient for another.
Model specific and model agnostic XAI
Generally, it can be said that there are two main approaches to developing interpretable models. One approach is to create simple, clear models instead of black-box systems. for instance from a decision tree you can easily extract decision rules. However, this is not always possible and sometimes more complex AI models are needed. Thus, the second approach is to provide post-hoc explanations for more complex or even entirely black-box models. The latter approach typically uses model-agnostic explainability methods which can be used for any machine learning model, from support vector machines to neural networks [3]. Model agnostic methods currently available include Partial Dependence Plots (PDPs), Individual Conditional Expectation (ICE) plots, global surrogate models, Shapley Additive Explanations (SHAP) and Local Interpretable Model-agnostic Explanations (LIME) [4,5].
For example, LIME helps to make the model’s predictions individually comprehensible. The method explains the classifier for a specific single instance. It manipulates the input data and creates a series of artificial data containing only a part of the original attributes. In the case of text data, different versions of the original text are created, in which a certain number of different, randomly selected words are removed. This new artificial data is then classified into different categories. Thus, through the absence or presence of specific keywords, we can see their influence on the classification of the selected text. In principle, the LIME method is compatible with many different classifiers and can be used with text, image and tabular data. It is possible to apply the same pattern to image classification, where the artificial data does not contain a part of the original words, but image sections (pixels) of an image [5].

Attention
Some black box models are not so black box anymore. In 2016, came out the first article that introduced a mechanism to allow a model to automatically (soft-)search for parts of a source sentence that are relevant to predicting a target word [6]. Then in 2017 followed the article Attention is All You Need [7], which introduced the attention mechanism and transformer models. There could be different ways to classify attention types, but two main ones are additive and dot product attention [8].
In general terms, the attention mechanism draws dependencies between input and output [9]. In traditional Deep Learning models (LSTMs, RNNs) the longer the input the harder for the model to retain relevant information from the past steps. That’s why we want to signal to the model what it should focus on and pay more attention to (while generating each output token at the decoder). In transformer models this problem does not exist because they use self-attention [10] throughout – every encoder and decoder layer have attention.
Models with the attention mechanism are currently dominating the leadership boards for abstractive summarization tasks [11, 12]. Attention is not only useful to improve the model performance, but it also helps us explain to the end-users of the AI system where (in the source text) the model paid attention to [13]. This is exactly what we did for one of our internal products to add even more value to the augmentation of the editorial workflow.

For this specific use case, we trained a Deep Learning model to generate a summary based on a source text. Per predicted token (as part of the summary), we obtain a distribution of attention scores over the tokens in the source text. We aggregated the attention vectors into an attention score per word in the source text, smoothed and normalized those values. We thus ended up with an attention score between 0 to 1 for each word in the source text (Figure 4 above), which we display to the end-users via text highlighting. The larger the attention score, the darker the text highlighting, and the more importance the model put on the respective word when generating the summary as shown in Figure 5 below [14].

Often many of the explanations rely on researchers’ intuition of what constitutes a ‘good’ explanation. This is problematic because AI explanations are often demanded by lay users, who may not have a deep technical understanding of AI, but hold preconceptions of what constitutes useful explanations for decisions made in a familiar domain.
We believe and propose that when you are deciding on how to explain your AI model to users who will be interacting with it, you should tailor these explanations to the needs of the users. Ideally, you should test different explainability methods with them and the testing environment should resemble a real-life set-up as much as possible because this helps to really understand which explainability methods work best and why. You should aim to gather both passive metrics (e.g. did the users make more edits to AI suggestions, were they faster or slower, etc.) as well as for direct feedback from users through interviews and surveys. However, you should also collect some feedback once the model has been put in active use as well and be always ready to iterate and improve your model as well as its explainability features.
READ MORE:
- Achieving sustainability in a digitally connected world
- How is digital construction improving safety and sustainability within the building sector?
- Huawei releases its 2020 sustainability report
- How AI Can assist sustainability in the healthcare industry
Join us for our talk at the Data Innovation Summit to learn how we selected explainability methods for our legal text summarization solution and lessons we learned in the process.
Explore the Data Innovation Summit
References
[1] Arrieta A. B. et al. (2020). Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Information Fusion 58: 82–115. arXiv:1910.10045. Retrieved from: https://arxiv.org/abs/1910.10045[2] Murdoch J. W. et al. (2019) Interpretable machine learning: definitions, methods, and applications, Proceedings of the National Academy of Sciences, Retrieved from: https://arxiv.org/abs/1901.04592[3] Molnar C. (2021) Interpretable Machine Learning: A Guide for Making Black Box Models Explainable. Retrieved from: https://christophm.github.io/interpretable-ml-book/[4] Sundararajan, M., et al. (2019) “The many Shapley values for model explanation.” Retrieved from: https://arxiv.org/abs/1908.08474[5] Ribeiro, M. et al. (2016) “Why should I trust you?: Explaining the predictions of any classifier.” Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. ACM.[6] Bahdanau, D. et al. (2016). Neural Machine Translation by Jointly Learning to Align and Translate. 3rd International Conference on Learning Representations, ICLR 2015: https://arxiv.org/abs/1409.0473[7] Vaswani, A. et al. (2017). Attention is all you need. Advances in Neural Information Processing Systems (p./pp. 5998–6008)[8] Lihala, A. (2019) Attention and its different forms. Blogpost onMedium: https://towardsdatascience.com/attention-and-its-different-forms-7fc3674d14dc[9] Weng L. (2018) Attention? Attention! Blogpost on Lil’Log: https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html#self-attention[10] Geeks for Geeks Editors. (2020) Self-attention in NLP. Blogpost on Geeks for Geeks: https://www.geeksforgeeks.org/self-attention-in-nlp/[11] Sanjabi, N. Abstractive Text Summarization with Attention-based Mechanism. Master Thesis in Artificial Intelligence: https://upcommons.upc.edu/bitstream/handle/2117/119051/131670.pdf[12] Ruder, S. Abstractive Summarization. NLP-progress:http://nlpprogress.com/english/summarization.html[13] Wiegreffe, S. et al. (2019) Attention is not not Explanation https://arxiv.org/abs/1908.04626[14] Norkute, M. et al. (2021). Towards Explainable AI: Assessing the Usefulness and Impact of Added Explainability Features in Legal Document Summarization. Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems. Association for Computing Machinery, New York, NY, USA, Article 53, 1–7. DOI:https://doi.org/10.1145/3411763.3443441
For more news from Top Business Tech, don’t forget to subscribe to our daily bulletin!
Follow us on LinkedIn and Twitter